一般回归模型和线性回归模型的关系
线性回归模型是一般回归模型的一个特例。
一般回归模型泛指所有以最小化均方误差为目标,寻找自变量 X到因变量Y的最优预测函数f(X)的方法,不限制f 的形式。
线性回归模型则在此基础上增加了具体假设:f(X) 是参数的线性组合(Xβ),且通常附带误差独立同分布、正态性、同方差等假设。
因此,一般回归模型是一个更大的框架,线性回归模型是其中最基础、最简单的一种参数化模型。
投影
在 Rn中,给定一个向量a及子空间W,如果在 W中存在向量b使
∥a−b∥=x∈Winf∥a−x∥则称 b是a在W中的投影。b是a在W上的投影⟺b∈W且a−b与W中所有向量正交
投影矩阵
在Rn中,设W是由向量a1,a2,…,ar张成的子空间,则W上的投影矩阵为P=A(A′A)−1A′。其中,A=[a1a2⋯ar]。
例题
请推导线性回归模型 Y=Xβ+ε 的最小二乘估计量。
线性回归模型
现在,我们先来了解一下回归模型。
回归分析:通过一组自变量(预测变量)来预测一个或者多个因变量(预测变量)的统计方法。也可用于评估预测变量对响应变量的影响。
r 个自变量 x1,x2,⋯,xr,因变量 Y。
- 例:Y=住房的当前市值,x1=居住面积,x2=位置,x3=去年的评估价值,x4=建筑质量
Y=均值+随机误差ϵ
- 均值:预测变量的连续函数(固定值)
- 误差ϵ:测量误差和其余未被考虑的变量所产生的效应(随机变量)。
式子列出来就是这样:
单个响应的线性回归模型:Y=β0+β1x1+⋯+βpxp+ϵ
你可以把它看作是一个非中心化的AR模型,只是自变量是因素而不是时间。 β 和 ϵ 是未知量是要求解的,其他的是可以观测得到。
这里只有一次观测,那观察多次呢?
Y 的 n 个观测值与因变量的联系
Y1Y2Yn=β0+β1x11+β2x12+⋯+βrx1r+ϵ1=β0+β1x21+β2x22+⋯+βrx2r+ϵ2⋮=β0+β1xn1+β2xn2+⋯+βrxnr+ϵn关于误差项 ϵ 的假定
- E(ϵj)=0
- Var(ϵj)=σ2
- Cov(ϵj,ϵk)=0, j=k
这里的误差项可以看作是白噪声序列,两者性质是一样的。
总所周知,数学家都很懒,对于上面的 Y 的 n 个观测值与预测变量的联系 那么长的式子,证明题里不得抄到累死。所以为了省力,有以下简洁的记法:
经典线性回归模型(矩阵形式)
Y=Xβ+ϵ
E(ϵ)=0,Cov(ϵ)=σ2I
其中β和σ2为未知参数。
Y1Y2⋮Yn=11⋮1x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1rx2r⋮xnrβ0β1⋮βr+ϵ1ϵ2⋮ϵn
好了,至此,我们知道了题目的前半句的含义,那后半句是说什么?以及这道题目是想让我们干什么?
说人话就是在矩阵形式的线性回归模型 Y=Xβ+ε 中,求出参数向量 β 的最小二乘估计量,并写出它的表达式。
最小二乘估计量
最小二乘法:寻找合适的β值,使得函数
S(β)=j=1∑n(yj−(β0+β1xj1+β2xj2+⋯+βrxjr))2=(Y−Xβ)′(Y−Xβ)=ϵ′ϵ达到最小,记为β^,称为β的最小二乘估计。
怎么理解呢? yj−(β0+β1xj1+β2xj2+⋯+βrxjr) 这个相当是一个真实值和拟合值的残差。
这里残差有正有负,要是直接加起来,可能会抵消,所以还要加个平方,最后再加起来。
因为是残差平方和嘛,所以肯定是越小越好的呗!用数学语言表达就是:
β^=argbminS(b)=(Y−Xb)′(Y−Xb)(残差平方和最小)这里的 b 是 β 的一个估计值。就相当于设了一个变量,因为还没求出来。
我们先不证明,先给出最小二乘的结果。
β^=(X′X)−1X′Y代入这个结果来预测以下 Y:(最优的没误差项了)
Y^=Xβ^=X(X′X)−1X′Y这个时候我们可以把Y前面的东西提取出来,命名为H。
H≡X(X′X)−1X′ 为自变量空间的投影矩阵。投影矩阵
看一下老师的定义:
投影矩阵:在 Rn中,设 W 是由向量a1,a2,…,ar张成的子空间,则W上的投影矩阵为P=A(A′A)−1A′。其中,A=[a1,a2,⋯,ar]。
文字可能很抽象,我们来画张图片:
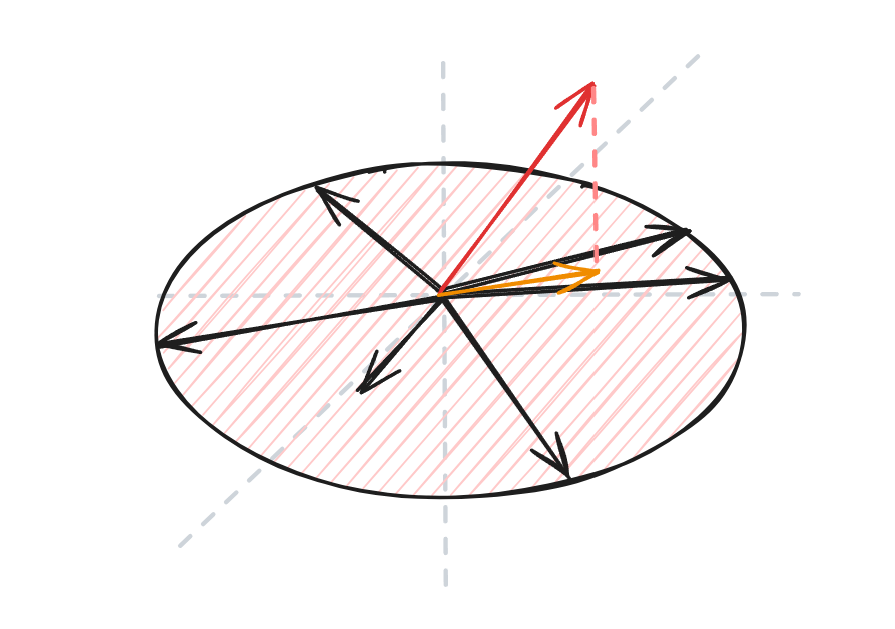
这个红色的空间就是 W,而投影矩阵所做的事就是把 红色的向量 投影到 W 这个空间,变为 橙色的向量。
所以对于 ∀a=u+v:u∈W,v⊥W,有 Pa=u。,因为v垂直,投影后长度为0。
投影矩阵还有一些比较好的性质:P′=P,Pn=P
最小二乘估计量的推导
绕了这么远,就是因为我们要用投影矩阵来推导最小二乘估计量。
我们把 Xβ 看作矩阵 X 的列空间 CXK(X) 中的所有向量。
CXK(X) 是什么?为什么我想起了一位故人…
CXK(X) 就是由所有可能的 Xβ 向量 或者说是 X 组成的向量空间。因为乘 β 只是让他在原有的空间内做变换,不会变幻整个空间。
所以你取什么名字都可以,我瞎取的。
最小二乘目标是让残差平方和最小:
β^=argbminS(b)=(Y−Xb)′(Y−Xb)(残差平方和最小)我们可以在 CXK(X) 空间中找到一个 Xβ=Y^ (拟合值)使它与 Y (实际值)的欧氏距离最短。
这个最优值在集合上是明确的,就是:从 Y 向子空间 CXK(X) 作垂线,垂足 Y^ 就是最优拟合值。
正好,这也可以让投影矩阵大展身手。
定义投影矩阵:
P=X(X′X)−1X′那么:
Xβ^=Y^=PYPY 就是 Y 到 蔡徐坤空间 的投影 Y^ 它是由 Xβ^ 构成的预测值。
我们代入 P 的表达式:
Xβ^=X(X′X)−1X′Y两边左乘X′:
X′Xβ^=X′X(X′X)−1X′Y由于 X′X 可逆,两边再同时左乘上 (X′X)−1 得
β^=(X′X)−1X′Y于是我们推导好了。
OLS 估计量(普通最小二乘估计量)的含义及优良性
β^=argbminS(b)=(Y−Xb)′(Y−Xb)(残差平方和最小)由投影的定义,有Xβ^=HY⟹β^=(X′X)−1X′Y。
其中,H≡X(X′X)−1X′为自变量空间的投影矩阵。
- 优良性:
- 无偏性:若满足一定基本假设,则E(β^∣X)=β。
- 一致性:若满足一定假设,且当样本量 n→∞时,有β^→β。
- 最优线性无偏估计 (BLUE):根据高斯-马尔科夫定理,在所有线性无偏估计量中,OLS 估计量的方差最小。
线性回归模型中两种平方和分解的形式
由 Y=Y^+(Y−Y^)及投影的性质,有Y′Y=Y^′Y^+(Y−Y^)′(Y−Y^)
由 Y−1Y=(Y^−1Y)+(Y−Y^)及投影的性质,有
总平方和(SST)(Y−1Y)′(Y−1Y)=回归平方和(SSR)(Y^−1Y)′(Y^−1Y)+残差平方和(SSE)(Y−Y^)′(Y−Y^)例题
已知均方误差 MSE(g)=E(Y−g(X))2。证明:E(Y∣X)=argmingMSE(g)。
先翻译成人话:那我问你:条件期望 E(Y∣X) 是让 MSE 取得最小的那个 g 函数吗?
重期望定理
E[E[Y∣X]]=E[Y]纯背的,没什么好说的,除非你想知道这么来的。
推导
我既然说了重期望法则,那说明肯定要用到,所以,还是和之前一样的构造,加一个减一个。
Y−g(X)=(Y−E[Y∣X])+(E[Y∣X]−g(X))平方算出来:
(Y−g(X))2=(Y−E[Y∣X])2+(E[Y∣X]−g(X))2+2(Y−E[Y∣X])(E[Y∣X]−g(X))再取期望,搞出MSE:
MSE(g)=E[(Y−E[Y∣X])2]+E[(E[Y∣X]−g(X))2]+2E[(Y−E[Y∣X])(E[Y∣X]−g(X))]我们还是一项一项看:
交叉项: E[(Y−E[Y∣X])(E[Y∣X]−g(X))]
这里,设 E[(Y−E[Y∣X])(E[Y∣X]−g(X))]=E(U) (内部为U) 那么利用一下重期望定理:
E(U)=E[E(U∣X)]=E[E[(Y−E[Y∣X])(E[Y∣X]−g(X))∣X]]我们做重期望是为了把 X 放入内层期望中,所以我们主要看内层。
E[(Y−E[Y∣X])(E[Y∣X]−g(X))∣X]这里,在给定 X 的条件下,可以把 (E[Y∣X]−g(X))(第二项)看作常数,从而提到外面:
E[(Y−E[Y∣X])(E[Y∣X]−g(X))∣X]=(E[Y∣X]−g(X))E[Y−E[Y∣X]∣X]在最后一项中:
E[Y−E[Y∣X]∣X]=E[Y∣X]−E[Y∣X]=0也算是结论吧…所以交叉项为零。
其余项
剩下的项写出来:
MSE(g)=E[(Y−E[Y∣X])2]+E[(E[Y∣X]−g(X))2]其中,第一项和 g(x) 无关,是固有的一项。 而第二项是和 g(x) 有关的,而且第二项是平方项,所以非负。
只要g(x)取的好,比如 g(X)=E[Y∣X] 时第二项为零,其他时候都大于0。
因此:
MSE(g)≥E[(Y−E[Y∣X])2]=MSE(E[Y∣X])等号成立当且仅当g(X)=E[Y∣X]。
MSE在ppt中没提及,以及这题结论比较多,没什么可以说的,只能背力。
例题
已知均方误差 MSE(β)=E(Y−X′β)2,β∗=[E(XX′)]−1E(XY)。证明
(1) β∗=argminβMSE(β);
翻译:β∗ 是让 MSE(β) 最小的那个 β 吗?
先展开平方项:
MSE(β)=E[Y2−2YX′β+β′XX′β] X′β 是一个标量,为了凑出 β∗ 里面的形式,需要乘上(X′β)′
把期望打开:
MSE(β)=E[Y2]−2E[YX′]β+β′E[XX′]β 为什么 β 可以提到期望的外面?
β是我们要评价的参数,不是随机变量,可以理解是待定的系数。
要让 MSE 最小,那就对β求导呗:
∂β∂MSE=−2E[XY]+2E[XX′]β=0稍微调一下位置:
β=[E(XX′)]−1E(XY)=β∗还要补充一句:
由于凸性,该点为全局最小值点,因此 β∗=argminβMSE(β)。
(2) 若 Y=β∗′X+ε,则 E(Xε)=0。
正常的回归是:Y=Xβ+ϵ
这里则是Y=β′X+ε,所以 β′X 是一个标量。标量你转个置也没什么事情:β∗′X=X′β∗
所以:
Y=X′β∗+ε两边左乘 X
XY=XX′β∗+Xε两边取期望
E[XY]=E[XX′]β∗+E[Xε]回顾上文,[E(XX′)]−1E(XY)=β∗,代入后上式后
E[XY]=E[XY]+E[Xε]⟹E[Xε]=0得证。
例题
令 β=A′Y为β的任意线性无偏估计量,即E(β∣X)=β,若 rank(X)=k+1,E(ε∣X)=0,E(εε′∣X)=σ2I,证明:Cov(β,β∣X)≥Cov(β^,β^∣X)。
代入 Y=Xβ+ε
E(A′Y∣X)=E(A′(Xβ+ε)∣X) =E(A′Xβ∣X)+E(A′ε∣X)=A′Xβ其中:
- E(A′ε∣X)=A′E(ε∣X)=A′0=0
- 给定 X 时,A,X,β是常数,所以:E(A′Y∣X)=A′Xβ
这里因为 β=A′Y
所以 E(A′Y∣X)=E(β∣X)=A′Xβ=β
所以得到 A′X=I
计算Cov(β,β∣X)
Cov(β~,β~∣X)=Cov(A′Y,A′Y∣X)=A′Cov(Y,Y∣X)A=A′Cov(ε,ε∣X)A=A′σ2IA其中:
- Cov(A′Y∣X)=A′Cov(Y∣X)A 这是一个运算法则,左乘原矩阵,右乘矩阵的转置。
- 模型为Y=Xβ+ε,在给定 X 的条件下, Xβ 是常数,所以Cov(Y,Y∣X)=Cov(ε,ε∣X)
计算Cov(β^,β^∣X)
Cov(β^,β^∣X)=Cov((X′X)−1X′Y,(X′X)−1X′Y∣X)=(X′X)−1X′Cov(Y,Y∣X)X(X′X)−1=σ2I(X′X)−1X′⋅X(X′X)−1=(X′X)−1σ2其中:
- β^ 是之前算的最小二乘估计量,β^=(X′X)−1X′Y
- 模型为Y=Xβ+ε,在给定 X 的条件下, Xβ 是常数,所以Cov(Y,Y∣X)=Cov(ε,ε∣X)
最后两者相减
Cov(β~,β~∣X)−Cov(β^,β^∣X)=σ2(A′A−(X′X)−1)=σ2(A′A−I(X′X)−1I)=σ2A′[I−H]A≥0解释
这里用到了前面得出的结论:A′X=I -> X′A=I
σ2(A′A−(X′X)−1)=σ2(A′A−I(X′X)−1I) 这里在 (X′X)−1 左右同乘单位阵。
把结论代入:
σ2(A′A−I(X′X)−1I)=σ2(A′A−A′X(X′X)−1X′A)这里是不是有点似曾相识?
H≡X(X′X)−1X′ 为自变量空间的投影矩阵。是的,我们的call back来了,这是投影矩阵。
化简后得到的这个 σ2A′[I−H]A≥0
大于等于0什么的就不证明了,毕竟你都看到这了,记一下不是轻而易举(雾)
常用残差诊断图的作用及诊断方法
残差对拟合值的散点图:用于诊断非线性关系。正确的图形中,残差应围绕零水平线均匀波动。
标准化残差对杠杆值散点图:用于识别自变量观测值中的异常值(高杠杆点)以及因变量观测值中的异常值(离群点),并通过Cook距离来识别强影响点。
标准化残差绝对值的平方根对拟合值散点图 (Scale-Location):用于诊断异方差问题。正确的图形中,标准化残差绝对值的平方根应围绕水平线均匀波动。
标准化残差的Q-Q图:用于检验残差是否服从正态分布。若图中的散点大致呈线性关系,则表明残差近似服从正态分布。
离群点、杠杆值、标准化残差、Cook距离和强影响点的含义
- 离群点:即为因变量观测值中的异常值。
- 杠杆值:反映了观测值 Yj对其拟合值Y^j 的影响程度,也可衡量自变量空间中某个数据点与其他数据点的距离,可用于识别自变量观测值中的异常值(高杠杆点)。
- 标准化残差:以标准差为单位计算出的残差,用于识别因变量观测值中的异常值。
- Cook距离:是一个综合了杠杆值和标准化残差的指标。
- 强影响点:指对模型系数有显著影响的数据点,它通过Cook距离来衡量。
近多重共线性对回归系数估计量的影响
- 自变量之间的相关性越强,ε^X(i)′ε^X(i)越小,β^i的方差越大。
- 仅近多重共线的自变量的方差会扩大。
方差膨胀因子的定义
方差膨胀因子(VIF)是用于衡量多重共线性的指标。其定义为
VIFi=ϵ^X(i)′ϵ^X(i)SSTi=SSEiSSTi=1−Ri21其中Ri2为第i 个自变量对其他自变量回归的决定系数。
R2可否作为模型选择的标准
不行。
局限性:R2会随自变量的增加而单调不减,因而不宜直接用于模型选择。从公式构造来看,R2实际上隐含地采用 n1SSE来估计误差方差σ2。然而,该估计量是有偏估计,无法准确反映模型真实解释能力的提升。因此,有必要对 R2 进行修正,以纠正上述偏误。
AIC和BIC的异同点
相同点:两者均权衡拟合优度(L(θ^))和模型复杂度( k)。
不同点:AIC 侧重于最小化预测误差;BIC 侧重于识别真实模型。
多元统计分析-第四章计算详解
周六 6月 06 2026 3871 字 · 16 分钟
